TL;DR
- 문제: Kafka S3 Sink Connector가 수십만 개의 작은 Parquet 파일 생성, Spark Job 성능 급락
- 원인:
schema.compatibility=NONE(기본값) 상태에서 구/신 스키마가 혼재되어 유입 - 해결:
schema.compatibility=BACKWARD로 설정 변경 (2편에서 추가 이슈 다룸)
“왜 Spark Job이 이렇게 느리지?” 😱
수요일 아침, 광고 지표 대시보드에서 이상한 숫자들이 보이기 시작했습니다. 원인을 추적하다 Spark History Server를 열어봤는데, 눈을 의심할 만한 숫자가 보였습니다.
읽은 파일 개수: 수십만 개

평소에는 수백 개였던 파일이 갑자기 수십만 개로 폭증했고, 각 파일의 크기는 고작 수십 KB에 불과했습니다. 무엇이 잘못된 걸까요?
이 글에서는 Kafka S3 Sink Connector의 schema.compatibility 설정 하나가 어떻게 문제를 일으켰는지, 그리고 타임라인 분석을 통해 원인을 어떻게 찾아냈는지 공유합니다.
무엇이 문제였을까?
참고: 이 글에서 사용되는 테이블명, 토픽명, 서비스명 등은 실제 환경을 일반화한 것입니다.
2025년 11월 19일 수요일 아침, ads.events.log Glue 테이블을 사용하는 광고 지표 대시보드에서 이상 징후를 발견했습니다. 추적해보니 두 가지 문제가 동시에 터져 있었습니다.
증상 1: 데이터 적재 지연
S3 Sink Connector의 Lag이 지속적으로 증가하고 있었습니다. 전날 데이터가 아직 S3에 적재되지 않은 상태였고, 이로 인해 집계 결과가 불완전했습니다.
증상 2: Spark Job 성능 급락
| 구분 | 정상 | 장애 |
|---|---|---|
| 파일 개수 | ~500개 | 수십만 개 |
| 파일 크기 | 수십~수백 MB | 수십 KB |
| Spark 처리 | 10분 | 2시간+ |
Small Files가 Spark 성능을 저하시킨 이유는 다음과 같습니다:
- 파일 메타데이터 조회: S3에서 각 파일의 크기, 위치 등을 확인하는 LIST/HEAD 요청 증가
- 드라이버 오버헤드: 수십만 개 파일의 메타데이터를 수집하고 실행 계획 수립
- S3 API 요청 증가: 작은 파일마다 별도 GET 요청 필요
처음에는 설정이 잘못 변경된 건 아닐까 의심했지만 최근 변경 이력이 없었습니다.
그렇다면 대체 무엇이 문제였을까요?
원인을 찾아서
타임라인 재구성
일단 타임라인부터 재구성해보기로 했습니다.
Producer Pod 역할
로그성 데이터를 Kafka Topic으로 전송하는 서비스이며, Kubernetes 환경에서 여러 Pod으로 운영됩니다. 이 Topic에는 S3 Sink Connector가 연결되어 데이터를 Parquet 포맷으로 S3에 적재합니다.
화요일 (11/18):
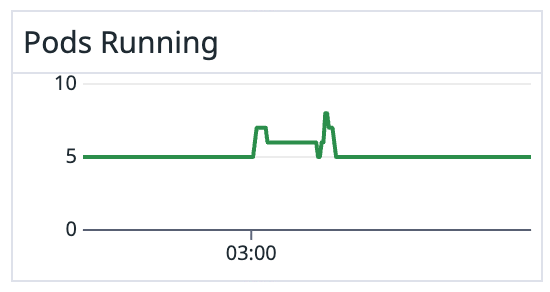
- 03:00 - Producer Pod 일부가 예기치 않게 재시작됨
- 03:00~15:00 - Kafka Topic에 구/신 스키마가 혼재된 메시지 유입
- 15:00 - Producer 전체 배포 완료, 이후부터는 신규 스키마만 유입
수요일 (11/19):
- 09:00경 - 광고 지표 이상 감지, 문제 추적 시작
흥미로운 패턴이었습니다. 15시를 기점으로 Kafka에 유입되는 메시지의 스키마가 달라졌습니다. 15시에 무슨 일이 있었던 걸까요?
첫 번째 단서: 혼재된 스키마
해당 Producer App은 성능 최적화를 위해 시작 시 Schema Registry에서 최신 스키마를 한 번만 로딩하고 캐시하도록 구현되어 있었습니다.
Schema Registry란?
Avro 스키마 버전을 중앙에서 관리하는 서비스입니다. 각 스키마 버전에는 고유한 Schema ID가 부여되고, Producer/Consumer가 이 ID로 스키마를 조회합니다.
그런데 이날의 상황은 특이했습니다:
- 15시에 신규 스키마를 사용하도록 배포 예정되어 있었습니다
- 스키마는 배포 전에 미리 Schema Registry에 등록해둔 상태였습니다
- 03시에 일부 Pod이 예기치 않게 재시작되면서 신규 스키마(latest) 를 로딩했습니다
- 재시작되지 않은 기존 Pod은 메모리에 캐시된 구 스키마를 계속 사용했습니다
결과적으로 Kafka Topic에는 구 스키마와 신규 스키마를 가진 메시지가 번갈아가며 유입되고 있었습니다.
메시지 순서: [Old, New, Old, Old, New, Old, New, New, Old, ...]두 번째 단서: schema.compatibility=NONE
S3 Sink Connector의 설정을 더 깊이 살펴보니, schema.compatibility 설정이 명시되어 있지 않아 기본값인 NONE으로 동작하고 있었습니다.
그리고 여기에 문제의 핵심이 있었습니다!
Parquet은 컬럼 기반 저장 포맷으로, 하나의 파일은 하나의 스키마만 가질 수 있습니다. 서로 다른 스키마를 가진 레코드는 같은 파일에 저장할 수 없습니다.
schema.compatibility=NONE 모드의 동작 원리:
- Connector가 스키마 변환을 수행하지 않고 각 메시지의 스키마를 그대로 사용합니다
- 따라서 다른 스키마 ID를 가진 메시지가 들어오면 현재 파일을 닫고(Flush) 새 파일을 생성해야 합니다
- 결과적으로 스키마가 번갈아 들어올 때마다 파일이 생성됩니다
이게 무슨 의미일까요?
1. Old 스키마 메시지 수신 → 파일 A에 기록
2. New 스키마 메시지 수신 → 스키마 변경 감지! → 파일 A 닫음 → 파일 B 생성
3. Old 스키마 메시지 수신 → 스키마 변경 감지! → 파일 B 닫음 → 파일 C 생성
4. Old 스키마 메시지 수신 → 파일 C에 기록 (스키마 동일)
5. New 스키마 메시지 수신 → 스키마 변경 감지! → 파일 C 닫음 → 파일 D 생성스키마가 번갈아 들어올 때마다 파일이 생성되었습니다. flush.size=10000(10,000개 레코드마다 파일 생성) 설정과는 전혀 무관하게 말이죠!
세 번째 단서: 화요일 15시 이후 데이터
화요일 15시에 Producer App 전체 배포가 완료되면서 모든 Pod이 신규 스키마를 사용하게 되었습니다. 그 순간부터 Kafka에 유입되는 데이터는 단일 스키마였습니다.
S3에 적재된 파일들을 확인해보니, 화요일 15시 이후 데이터는 정상 크기의 파일로 생성되어 있었습니다. 03시~15시 사이의 데이터만 수십만 개의 작은 파일로 쪼개져 있었던 것입니다.
바로 이 지점에서 모든 퍼즐 조각이 맞춰졌습니다.
문제 상황 전체 그림
이제 문제 상황을 전체 파이프라인 관점에서 다시 정리해보겠습니다:

정리하면:
- 일부 Pod 재시작으로 신/구 스키마가 Kafka Topic에 혼재
- S3 Sink Connector(schema.compatibility=NONE)가 스키마 변경마다 파일 분리
- 수십만 개의 Small Files가 S3에 적재
- Spark Job이 과도한 파일 수로 인해 성능 급격히 저하
- S3 업로드 오버헤드로 Connector Lag 누적 → 데이터 적재 지연
긴급 대응
단기 조치
파이프라인이 회사 광고 시스템 지표 측정에 사용되는 핵심 데이터였기 때문에 daily 지표 파악에 문제가 있었습니다. 문제를 파악한 즉시 두 가지 조치를 취했습니다.
-
Connector Scale-out
tasks.max를 증설하여 병렬 처리량을 늘렸습니다- 목표: 03~15시의 혼재된 데이터로 인한 Lag 을 빠르게 해소하고, 15시 이후 정상 데이터가 유입될 수 있도록 처리
- Lag을 빠르게 해소할 수 있었습니다
주의사항:
- Kafka Topic의 파티션 개수보다 많은 task를 생성해도 효과가 없습니다
- 각 task는 독립적인 S3 연결을 사용하므로 너무 많이 늘리면 네트워크 부담 증가
- S3 버킷의 request rate limit도 고려해야 합니다
-
File Compaction ETL
- 이미 생성된 수만 개의 작은 파일을 읽어서 큰 파일로 병합하는 ETL 작업을 수행했습니다
- Downstream Spark Job의 성능을 정상화할 수 있었습니다
근본 원인 해결을 위한 검토
장기적으로는 두 가지 개선 방안을 검토했습니다:
옵션 1. schema.compatibility 설정 변경
# 현재
schema.compatibility=(설정 없음, Default=NONE)
# 제안
schema.compatibility=BACKWARD기대 효과:
- BACKWARD 호환성: 신규 스키마가 구 스키마 데이터를 읽을 수 있음을 보장합니다
- Projection 기능: 구 스키마 데이터를 신규 스키마로 변환하여 저장
- 예: v753 데이터가 들어와도 v758 스키마로 변환하여 같은 파일에 기록
- 새로 추가된 필드는 default 값으로 채워지고, 삭제된 필드는 무시됩니다
- 스키마가 번갈아 들어와도 파일을 쪼개지 않음
옵션 2. Producer Schema 버전 명시
Producer 설정에 사용할 Schema Version을 명시적으로 지정하는 방안:
장점:
- Pod이 언제 재시작되더라도 설정된 버전의 스키마만 사용
- 의도하지 않은 “부분 업그레이드” 방지
단점:
- 스키마 변경 시마다 애플리케이션 설정 변경과 배포 필요
- 운영 복잡도 증가
- Rolling 배포 시 결국 일시적으로 스키마 버전이 불일치하는 순간이 발생
팀 내 논의 결과, Option 2로는 근본적인 해결이 어렵다고 판단했습니다. Avro 스키마의 하위호환성을 유지하면서 첫 번째 방안(schema.compatibility=BACKWARD) 을 적용하기로 결정했습니다.
schema.compatibility 옵션 이해하기
혹시 여러분도 S3 Sink Connector를 사용하고 계신가요? 그렇다면 이 설정을 꼭 확인해보세요:
| 설정값 | 동작 방식 | 파일 생성 빈도 | 적합한 상황 |
|---|---|---|---|
| NONE | 스키마 변환 없이 원본 그대로 저장 → 스키마 ID가 바뀌면 파일 생성 | 높음 ⚠️ | 스키마가 거의 변경되지 않는 환경 |
| BACKWARD | 구 스키마 → 신규 스키마로 projection → 같은 파일에 계속 저장 | 낮음 ✅ | 스키마가 자주 변경되는 환경 (추천) |
| FORWARD | 신규 스키마 → 구 스키마로 projection | 낮음 | Consumer가 구버전인 환경 |
| FULL | 양방향 projection 지원 (BACKWARD + FORWARD) | 낮음 | 가장 유연한 호환성이 필요한 환경 |
대부분의 경우 BACKWARD 모드가 적합합니다.
이번 경험에서 배운 것
1. Default 설정을 믿지 말기
솔직히 말하면, 문서를 꼼꼼히 읽지 않은 게 아쉽습니다. schema.compatibility의 기본값이 NONE이라는 사실을 몰랐습니다. “설마 기본값이 문제가 되겠어?”라고 생각했던 제 자신이 부끄럽습니다.
앞으로는 새로운 컴포넌트를 도입할 때 모든 주요 설정을 반드시 확인하겠습니다.
2. 타임라인 분석의 힘
“언제부터 문제가 시작되었고, 언제 끝났는가?”를 파악하는 것만으로도 원인의 실마리를 찾을 수 있었습니다.
특히 15시 전후로 동작이 달라진다는 점을 발견한 것이 결정적이었습니다.
3. Connector Lag 모니터링의 부재
S3 Sink Connector의 Lag 모니터링이 없었습니다. 만약 Lag 알림이 설정되어 있었다면 화요일 오전에 이미 이상 징후를 감지할 수 있었을 것입니다. 다음 날 대시보드에서 문제를 발견하는 대신, 문제가 발생한 당일에 조기 대응이 가능했을 겁니다.
지금 바로 확인해보세요
여러분의 S3 Sink Connector는 어떻게 설정되어 있나요?
# Connector 설정 확인 (localhost:8083은 환경에 맞게 변경)
curl -X GET http://localhost:8083/connectors/your-connector/config \
| jq '.["schema.compatibility"]'만약 결과가 null(설정 안됨 → 기본값 NONE 적용)이거나 "NONE"이라면, 스키마가 변경될 때 동일한 문제가 생길 위험이 있습니다.
자주 묻는 질문
Q: schema.compatibility 기본값은 무엇인가요?
A: 기본값은 NONE입니다. 이 설정에서는 스키마 ID가 변경될 때마다 현재 파일을 닫고 새 파일을 생성합니다.
Q: BACKWARD와 NONE 모드의 차이는 무엇인가요?
A: NONE은 스키마 변환 없이 원본 그대로 저장하므로 스키마가 바뀌면 파일을 분리합니다. BACKWARD는 구 스키마 데이터를 신규 스키마로 projection하여 같은 파일에 계속 저장할 수 있습니다.
Q: Small Files가 Spark 성능에 영향을 주는 이유는?
A: 파일마다 S3 LIST/HEAD/GET 요청이 필요하고, Spark 드라이버가 수십만 개 파일의 메타데이터를 수집하는 오버헤드가 발생합니다. 또한 각 파일마다 별도의 Task가 생성되어 스케줄링 오버헤드가 증가합니다.
Q: flush.size 설정은 이 문제와 관련이 있나요?
A: flush.size는 레코드 개수 기준으로 파일을 분리하는 설정입니다. 하지만 스키마가 변경되면 flush.size와 무관하게 파일이 분리되므로, 이 문제의 직접적인 원인은 아닙니다.
다음 편 예고
BACKWARD로 바꾸면 해결될 줄 알았는데… 테스트 환경에서 또 파일이 쪼개졌습니다.
문서에 있지만 쉽게 지나치는 connect.meta.data라는 복병이 기다리고 있었습니다.
2편: connect.meta.data 설정이 원인에서 계속됩니다.
참고 자료
Confluent 문서:
- S3 Sink Connector - Schema Evolution
- S3 Sink Connector - Configuration Options (schema.compatibility)
커뮤니티: